
BIG DATA
Big data are large sets of raw, often unstructured data. Organizations used to purge this data because it was considered low quality and storage costs were high. Now storing data is much less expensive, so companies everywhere are looking for ways to harness this information to provide better insight into customer behaviors, analyze trends, and increase revenues.
The problem is how. Traditional data infrastructures can’t handle large amounts of data cost-effectively. Big data doesn’t fit neatly into relational databases making it difficult to store, manage, and analyze.
Adriot understands that big data is part of a whole solution that includes your existing data management systems. Our expert database consultants know how to build and configure your data infrastructure, so that it can manage all of your data—structured and unstructured—cost-effectively. Our extensive expertise in relational and non-relational databases combined with our experience implementing big data technologies, like Hadoop, and NoSQL technologies, like MongoDB and Cassandra, means we can help you develop a reliable solution that enables you to capture and store big data to be used and analyzed at another time. Having both relational and unstructured data experts on-board means that you will get a solution that truly fits your requirements

Hadoop:
Hadoop is the platform of choice for big data analytics; however, getting started with Hadoop can be challenging. Very few companies have the required expertise to build an Hadoop production cluster and integrate it into their existing data infrastructure.
Adriot experts can help you use Hadoop for large-scale data processing and analysis. Starting from use-case discovery, we will help you figure out where Hadoop fits into your existing data infrastructure. Adriot’s unique expertise with both Hadoop and most major relational databases give us both the knowledge and the perspective to know when Hadoop is the correct solution and how to integrate it into existing enterprise data workflows.

Adriot will help you set up a proof of concept, showing stakeholders within the organization the advantage Hadoop brings to enterprise data processing. We will show you how to analyze data that was impractical to analyze before, or how to use Hadoop to speed up existing ETL processes. When you are ready to take the solution to production, Adriot will be there to plan the cluster with you, size the capacity to accommodate future growth, integrate the cluster into existing systems and workflows, and build the necessary operational processes that a production cluster will require. We support on premise Hadoop Clusters or in the Cloud.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
The project includes these modules:
• Hadoop Common: The common utilities that support the other Hadoop modules.
• Hadoop Distributed File System (HDFS™): A distributed file system that provides high- throughput access to application data.
• Hadoop YARN: A framework for job scheduling and cluster resource management.
• Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
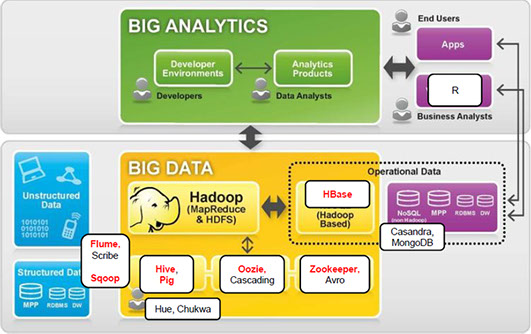
• Ambari™: A web-based tool for provisioning, managing, and monitoring Apache Hadoop clusters which includes support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig and Sqoop. Ambari also provides a dashboard for viewing cluster health such as heatmaps and ability to view MapReduce, Pig and Hive applications visually alongwith features to diagnose their performance characteristics in a user-friendly manner.
• Avro™: A data serialization system.
• Cassandra™: A scalable multi-master database with no single points of failure.
• Chukwa™: A data collection system for managing large distributed systems.
• HBase™: A scalable, distributed database that supports structured data storage for large tables.
• Hive™: A data warehouse infrastructure that provides data summarization and ad hoc querying.
• Mahout™: A Scalable machine learning and data mining library.
• Pig™: A high-level data-flow language and execution framework for parallel computation.
• Spark™: A fast and general compute engine for Hadoop data. Spark provides a simple and expressive programming model that supports a wide range of applications, including ETL, machine learning, stream processing, and graph computation.
• ZooKeeper™: A high-performance coordination service for distributed applications.
Apache Hadoop YARN is the data operating system for Hadoop 2.0. YARN enables a user to interact with all data in multiple ways simultaneously, making Hadoop a true multi-use data platform and allowing it to take its place in a modern data architecture.
Keeping Up with Change
The Apache Hadoop ecosystem is rapidly evolving, and most organizations don’t have the resources to stay on top of every version of Hadoop or the latest tools. Adriot keeps up with the ecosystem, ensuring our customers are able to take advantage of all the advances the community has to offer.
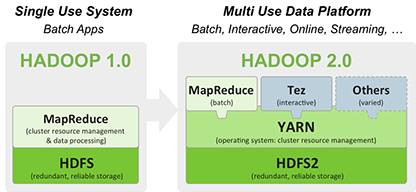
Hadoop’s Momentum Is Unstoppable
Divide and conquer: That’s the simple truth of Hadoop. At its core, Hadoop is a distributed file systemand distributed MapReduce processing framework that both stores and processes data by dividing workloads across three, five, or thousands of servers. Forrester defines a big data Hadoop solution as:
A distributed data platform that includes, extends, and augments Apache Hadoop (Common,HDFS, YARN, MapReduce) as a core component of the solution, supports Hadoop-related projects, and adds differentiated features that make it attractive to enterprises.
Hadoop is unstoppable as its open source roots grow wildly and deeply into enterprise data management architectures. Its refreshingly unique approach to data management is transforming how companies store, process, analyze, and share data of any size and structure. Forrester believes that Hadoop is a must-have data platform for large enterprises, forming the cornerstone of any flexible future data management platform.1 If you have lots of structured, unstructured, and/or binary data, there is a sweet spot for Hadoop in your organization.
Adriot Solutions Private Limited
Tangellamudi complex,First Floor,
NTR Circle patamata
VIJAYAWADA, ANDHRA PRADESH
Pincode : 520010
Phone +91 08666666010
E_mail: contactus@adroit.com
© 2015 Adriot SOLUTIONS PVT LTD
PARTNERS :

